The Data Center Professionals Network
The Global Database of Data Center Industry Expertise
RSS
Installing new Insider’s build Windows Server vnext NVMeoF, host initiator
Installing new Insider's build Windows Server vnext NVMeoF, host initiator
A few weeks ago, Microsoft released a new Insider's build of Windows Server vnext with NVMeoF host initiator. This post looks at installing and setting up the new initiator for testing. Granted, this is for testing and evaluating the NVMe over Fabric (NVMeoF) that supports TCP and RDMA for networked block storage with a Windows Server vnext host, and a Linux test target. Given that this is for a simple test and trying things out, you will want to adjust some of the security and access control settings on both the initiator and target sides.
Whats Needed
For the host NVMeoF initiator, you will need a current version of the insider build release of Windows Server vnext available here. You will also need some type of NVMeoF target, such as a storage system or platform that supports NVMeoF via TCP or RDMA, or a test initiator, for example, on a Linux system. For my test target, I set up an Ubuntu 25 Linux server with a small 50GB device to export as an NVMeoF device.
On the Ubuntu Linux server (e.g NVMeoF target)
sudo apt install nvme-cli -y sudo modprobe nvmet sudo modprobe nvmet-tcp lsmod | grep nvmet You should then see something like the following: nvmet_tcp 45056 1 nvmet 249856 7 nvmet_tcp nvme_core 241664 4 nvmet,nvme_tcp,nvme,nvme_fabrics nvme_keyring 20480 5 nvmet,nvme_tcp,nvmet_tcp,nvme_core,nvme_fabrics nvme_auth 28672 2 nvmet,nvme_core Continue with the NVMeoF target setup: sudo mount -t configfs none /sys/kernel/config cd /sys/kernel/config/nvmet # define your nqn which can be what ever you like, or have sudo mkdir subsystems/nqn-2026-03.com:nvme.storageio01 # since this is for testing, this is being loose with access control echo 1 | sudo tee subsystems/nqn-2026-03.com:nvme.storageio01/attr_allow_any_host sudo mkdir subsystems/nqn-2026-03.com:nvme.storageio01/namespaces/1 # specify device to use as target, the device could be a partition, volume, file, etc echo /dev/sdb | sudo tee subsystems/nqn-2026-03.com:nvme.storageio01/namespaces/1/device_path echo 1 | sudo tee subsystems/nqn-2026-03.com:nvme.storageio01/namespaces/1/enable # You can select what port you want to use. For testing, used 4420 sudo mkdir ports/4420 echo tcp | sudo tee ports/4420/addr_trtype echo 192.168.1.205 | sudo tee ports/4420/addr_traddr echo 4420 | sudo tee ports/4420/addr_trsvcid echo ipv4 | sudo tee ports/4420/addr_adrfam # For non-testing, you can adjust access to suit your needs sudo ufw allow 4420/tcp # now make the target accessible sudo ln -s /sys/kernel/config/nvmet/subsystems/nqn-2026-03.com:nvme.storageio01 /sys/kernel/config/nvmet/ports/4420/subsystems/nqn-2026-03.com:nvme.storageio01 # now lets see if there is a listener sudo ss -ltnp | grep 4420 # Should see something like this: LISTEN 0 128 192.168.1.205:4420 0.0.0.0:* # now lets discover whats out there based on what we have setup sudo nvme discover -t tcp -a 192.168.1.205 -s 4420 # should see something like this: Discovery Log Number of Records 2, Generation counter 2 =====Discovery Log Entry 0====== trtype: tcp adrfam: ipv4 subtype: current discovery subsystem treq: not specified, sq flow control disable supported portid: 4420 trsvcid: 4420 subnqn: nqn.2014-08.org.nvmexpress.discovery traddr: 192.168.1.205 eflags: none sectype: none =====Discovery Log Entry 1====== trtype: tcp adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 4420 trsvcid: 4420 subnqn: nqn-2026-03.com:nvme.storageio01 traddr: 192.168.1.205 eflags: none sectype: none # if you want to connect from the Linux server sudo nvme connect -t tcp -a 192.168.1.205 -s 4420 -n nqn-2026-03.com:nvme.storageio01 # and then list the targets nvme list # you should see something like this: Node Generic SN Model Namespace Usage Format FW Rev --------------------- --------------------- -------------------- ---------------------------------------- ---------- -------------------------- ---------------- -------- /dev/nvme0n1 /dev/ng0n1 eab7bd175e01b9dbbba5 Linux 0x1 53.69 GB / 53.69 GB 512 B + 0 B 6.17.0-1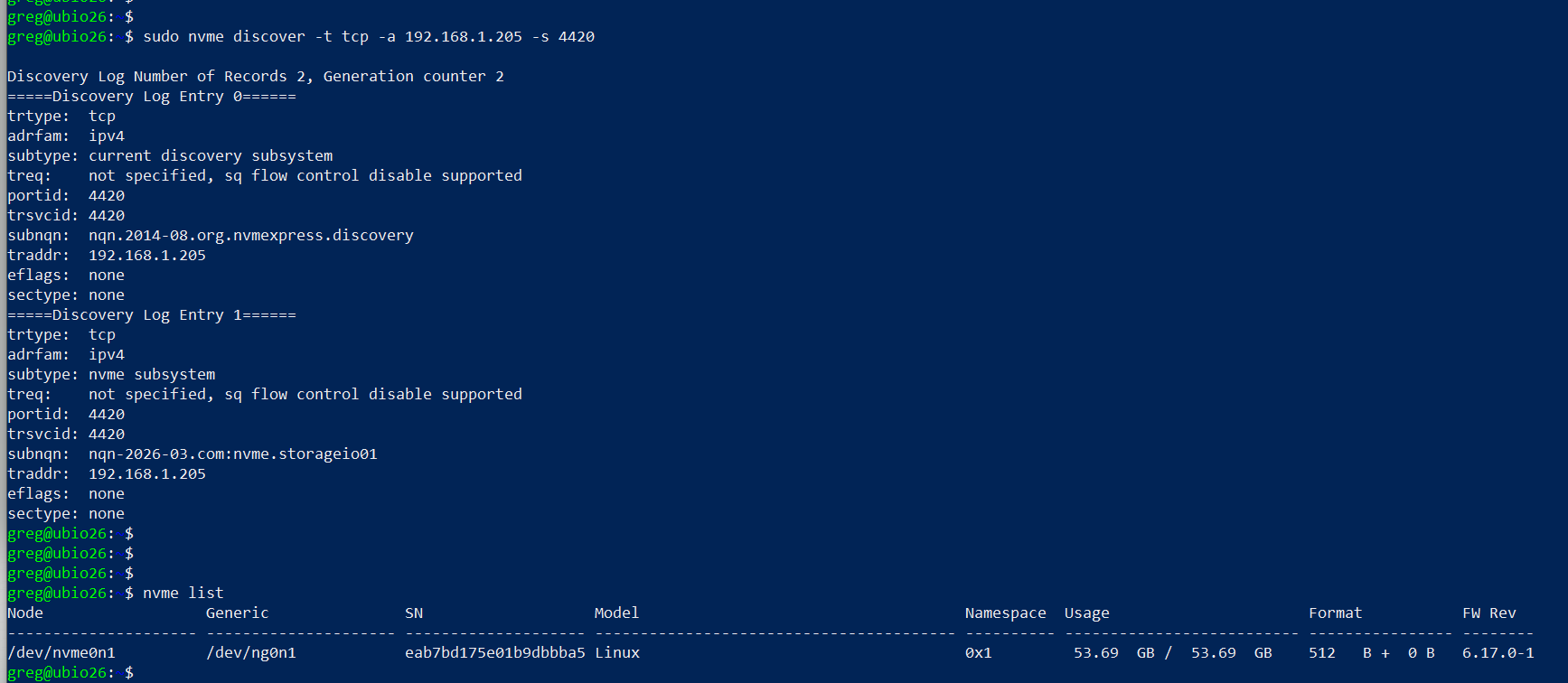
On Windows Server vnext (NVMeoF Initiator)
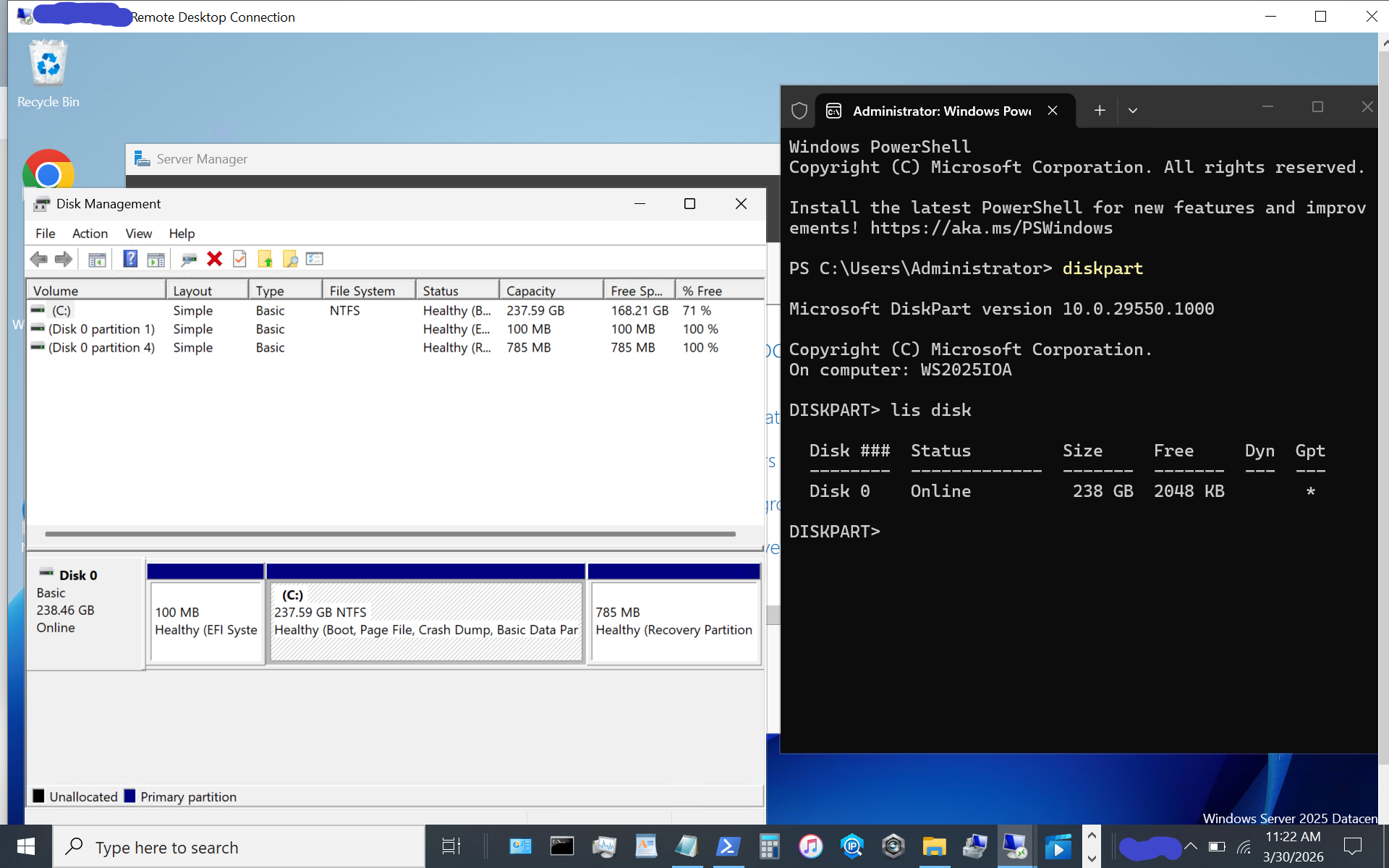
Now, on your Windows Server vnext, open a command window with elevated access (e.g., Run as Administrator) and use the following, making note of the parameters from the target (e.g., IP address, port 4420, nqn).
Here is a screen shot of the host initiator before the NVMeoF target appears.
 Now display available NVMeoF initiators using this command:
nvmeofutil.exe list -t ia
Now display available NVMeoF initiators using this command:
nvmeofutil.exe list -t ia
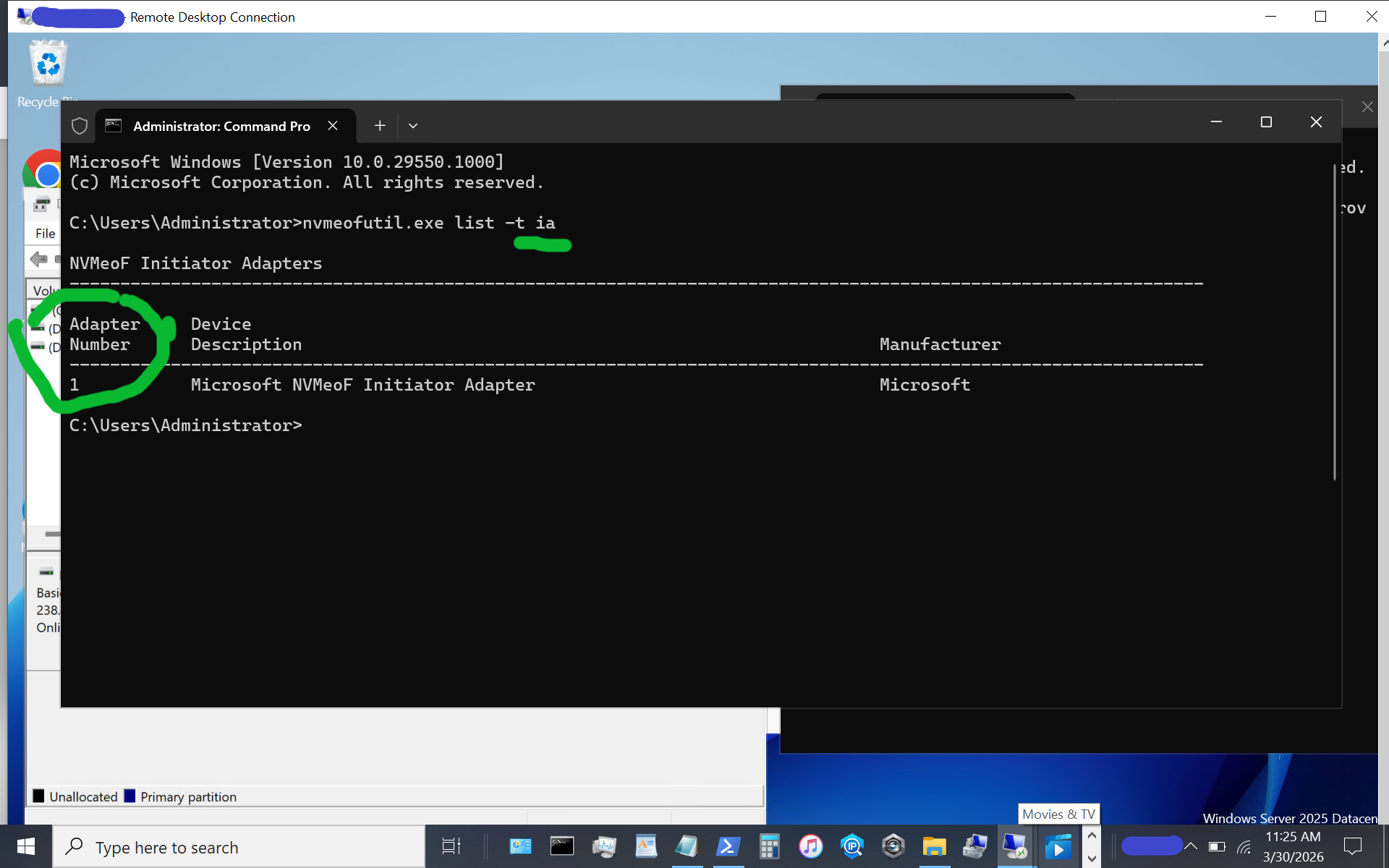 Note the host adapter number (e.g., 1) which will be used in the next step to get host gateway information.
nvmeofutil.exe list -t sp -ia 1
Note the host adapter number (e.g., 1) which will be used in the next step to get host gateway information.
nvmeofutil.exe list -t sp -ia 1
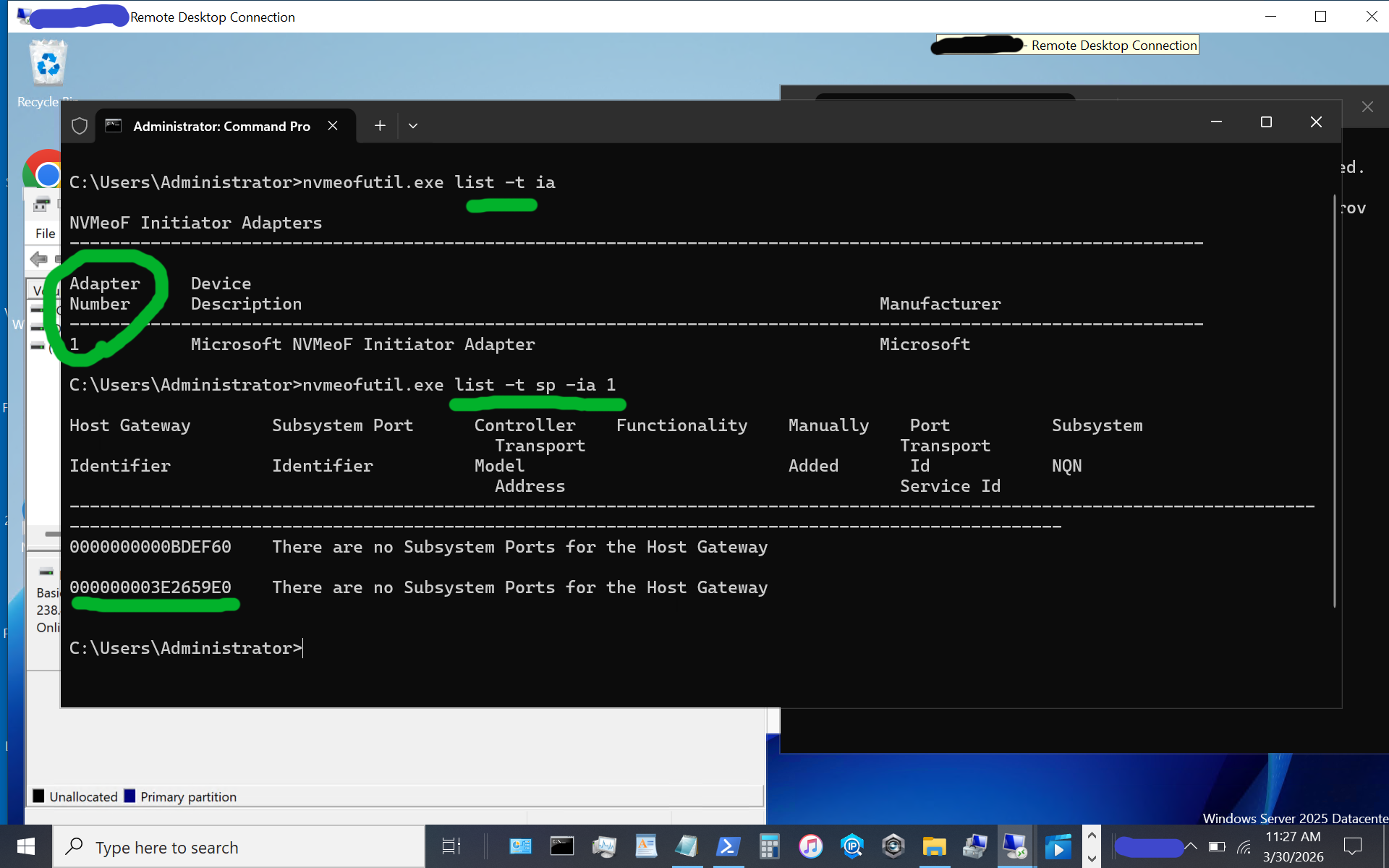
Note the host gateway, target IP address, target port, and target nqn. Also note that there is an IPV6 and IPV4, in this example there is no IPV6 being used, so we are using the 2nd item (e.g. IPV4).
nvmeofutil.exe add -t sp -ia 1 -hg -dy true -pi 1 -nq nqn-2026-03.com:nvme.storageio01 -ta 192.168.1.205 -ts 4420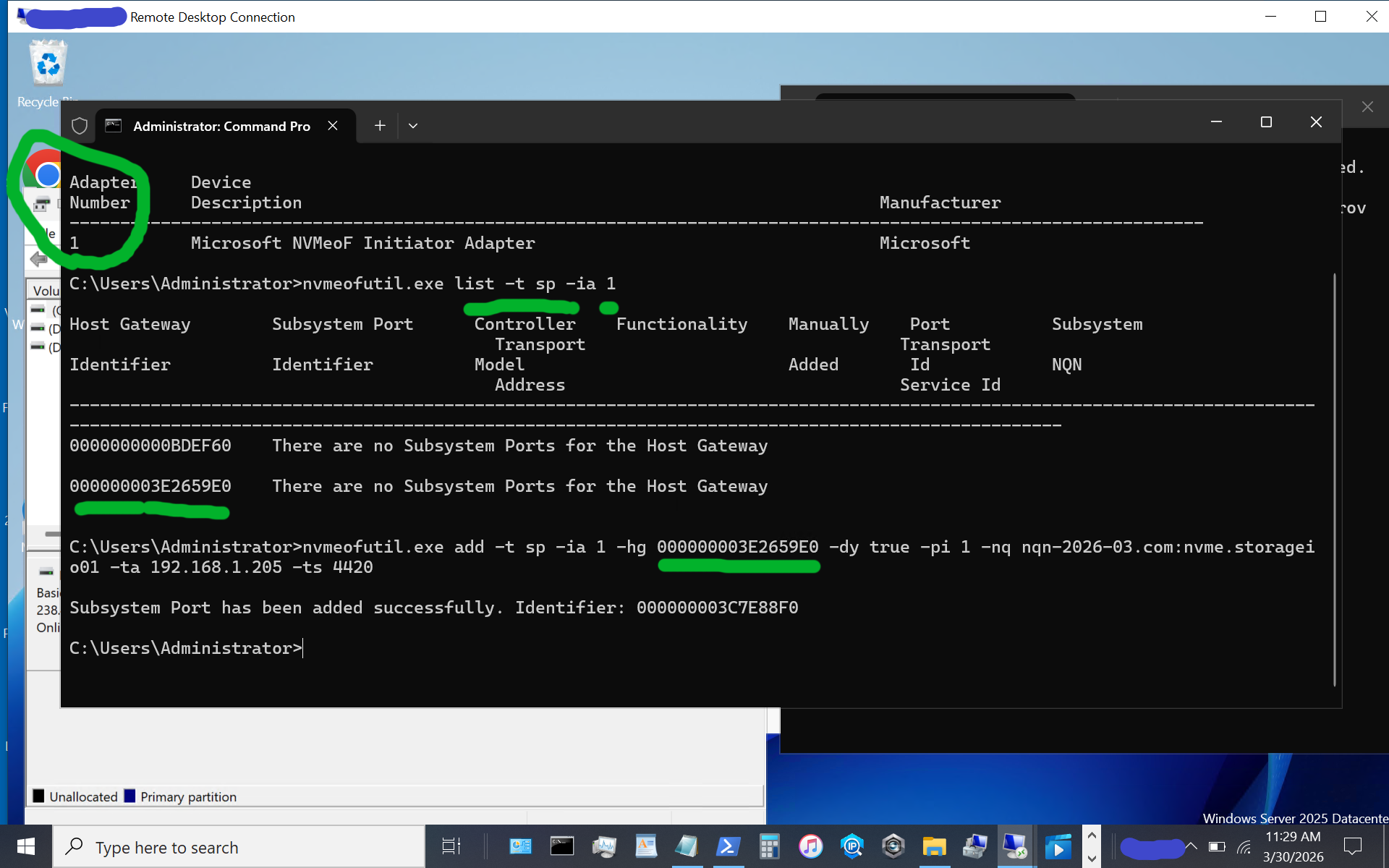 Now, let's identify the target subsystem ID.
nvmeofutil.exe list -t sp -ia 1
Now, let's identify the target subsystem ID.
nvmeofutil.exe list -t sp -ia 1
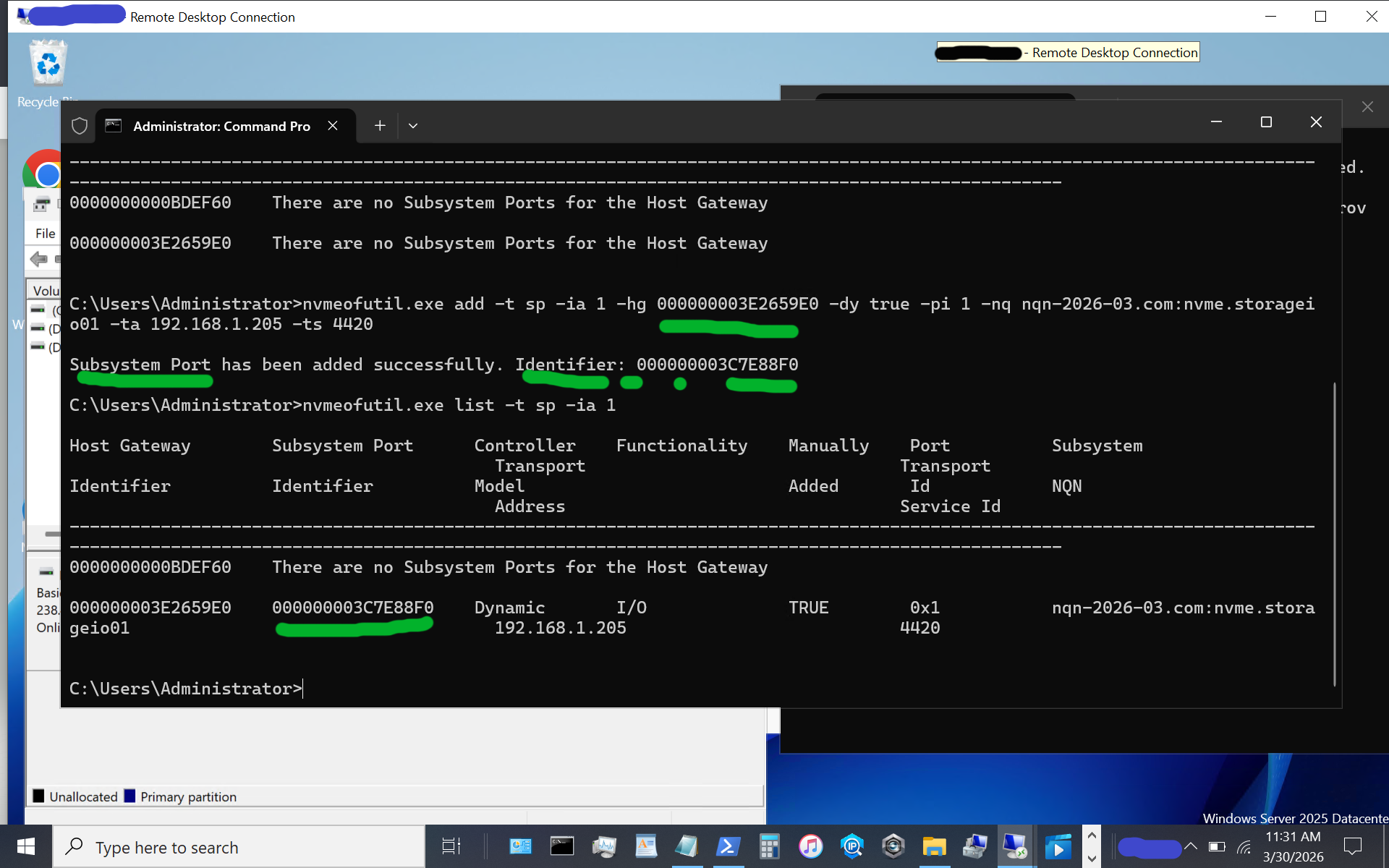
Now, let's use the subsystem port from above to connect to the target. Note that in some of the instructions I have seen, there is a reference to sp without an sp shown; thus, the previous steps help identify the sp to use.
nvmeofutil.exe connect -ia 1 -sp 000000003C7E88F0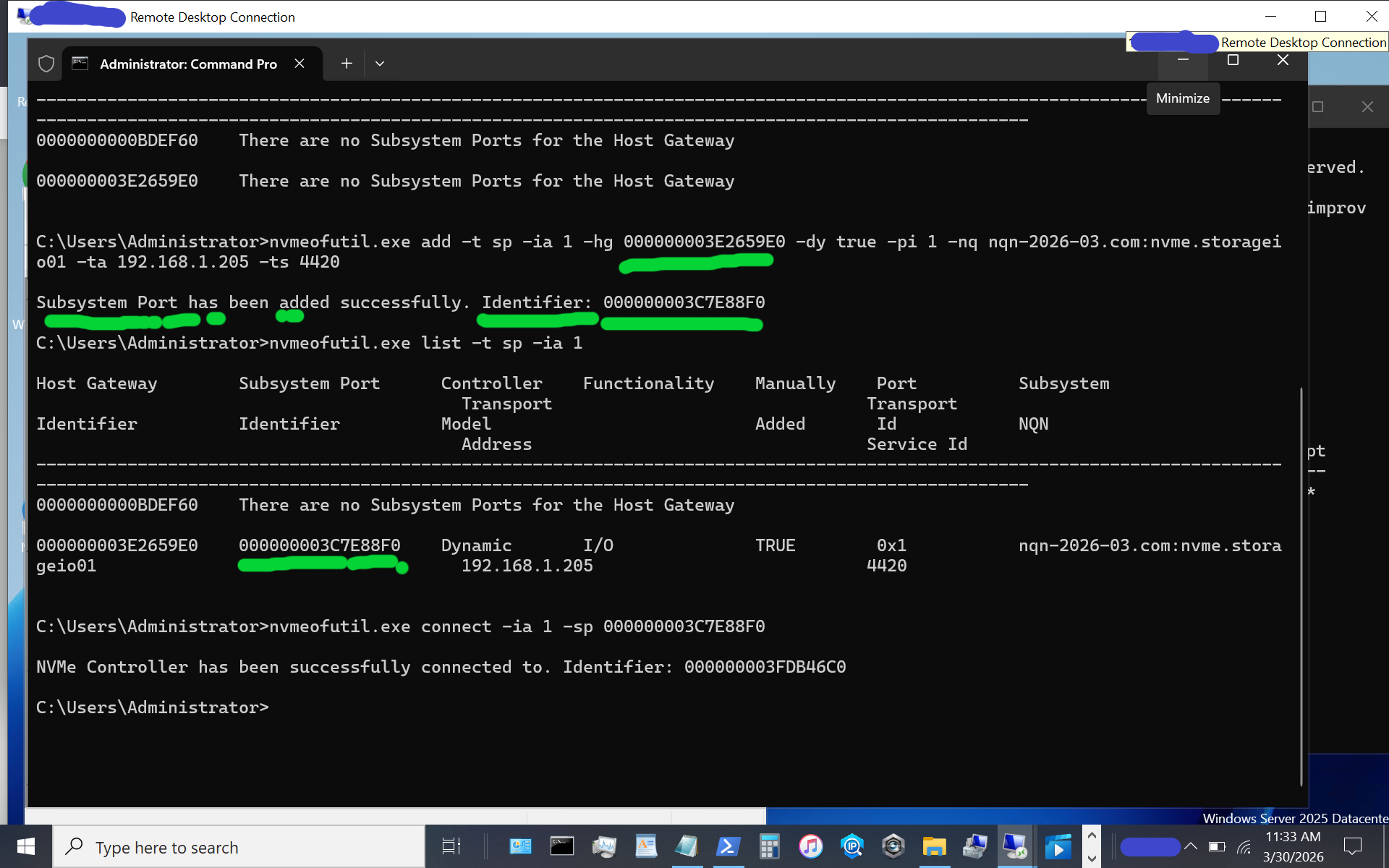
Congratulations, at this point, you should see a new disk or volume appear on your Windows Server vnext host system.
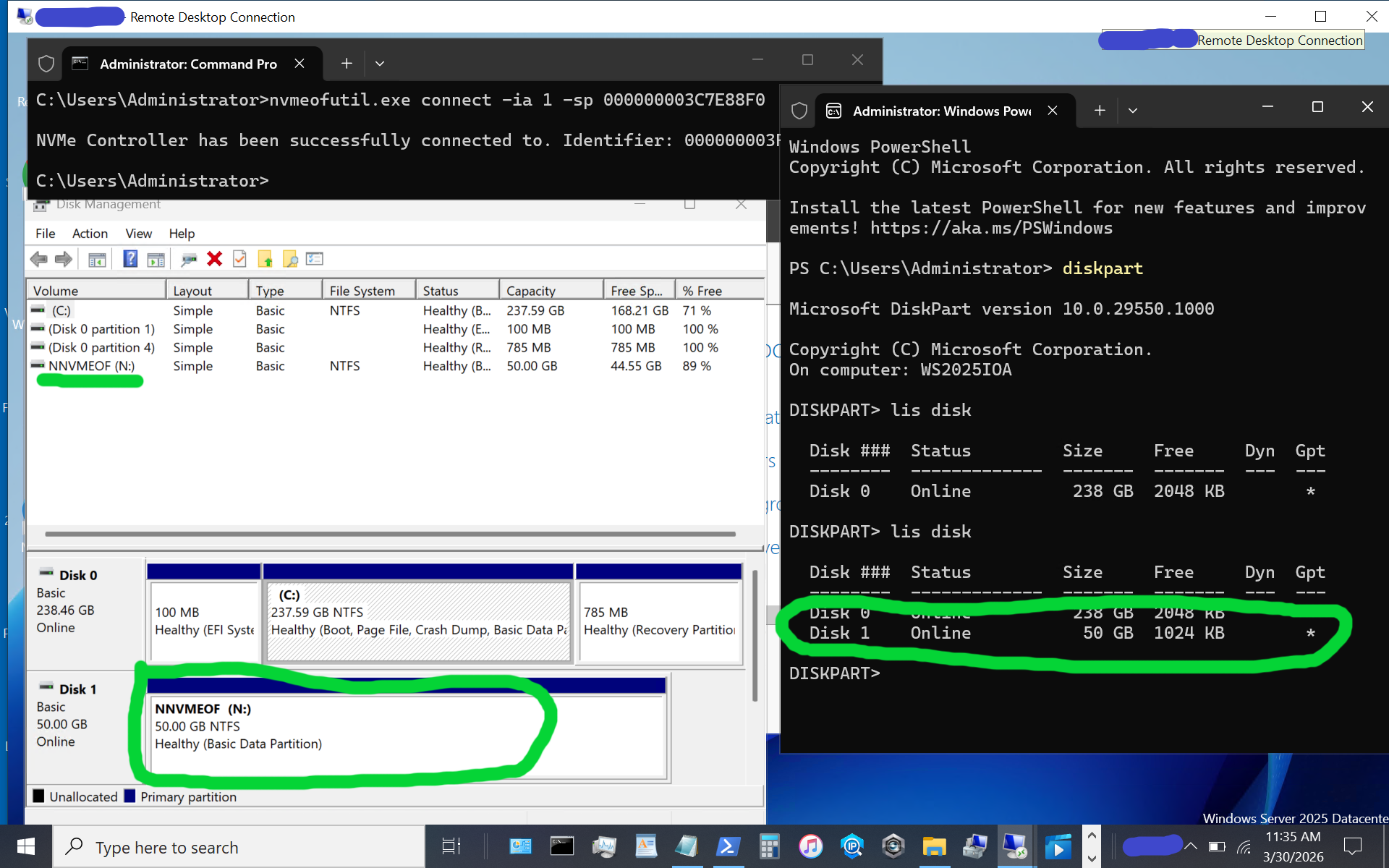
The above image shows what appears when using diskpart, as well as the disk format utility, or use your preferred command, PowerShell script, or tool. If the disk or volume has not yet been used, it must be initialized and formatted. Otoh, as in this example, the disk volume had previously been initialized and formatted as a simple NTFS volume.
Again, reiterating, the above is for simple testing and evaluation, with loose security and persistence that you will want to tighten up as needed. The whole process is pretty easy as long as you don't make any typos, for example, with nqn or other items.
Additional Resources Where to learn more
Microsoft Windows Server Insider Build NVMeoF Initiator (Blog post) NVMe Linux Driver and related info Announcing Native NVMe in Windows Server 2025 (Microsoft Post) Introducing the Windows NVMe-oF Initiator Preview in Windows Server Insiders Builds (Microsoft Post) Windows Server Insider Builds (Microsoft Downloads) ToE NVMeoF TCP Performance Boost Performance Reduce Costs (blog post) TheNVMeplace.com (Various NVMe resources) Azure Cloud Storage here (Microsoft Post) Microsoft Azure Data Box (Blog Post) Azure Elastic SAN from Cloud to On-Prem here (Blog Post) Cloud and Software Defined Data Infrastructure topics hereAdditional learning experiences along with common questions (and answers) pertaining to SCSI, Fibre Channel, NVMe, Cloud, Hardware, Software, Services, techniques, server, storage, I/O networking, data protection among other topics are found in my Software Defined Data Infrastructure Essentials book.

What this all means
With the insiders preview of Windows Server vnext you have the opportunity to try out the new NVMeoF initiator using TCP and RDMA including on Ethernet based fabric networks. The current insiders build utilizes the nvmeofutility.exe for initial testing, evaluations and experiments while future releases should see other management tools and interfaces such as Powershell cmdlets among others.
Ok, nuff said. Cheers GsGreg Schulz - Ten time Microsoft MVP Cloud and Data Center Management and Azure Storage, along with previous ten-time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.
Its Time for NVMeoF to let iSCSI begin its slow retirement journey
Why Its Time for NVMeoF
Its Time for NVMeoF to let iSCSI begin its slow retirement journey for networked shared block storage. Dating back to the late 1990s and early 2000s, iSCSI encapsulates the SCSI command set over a TCP/IP (IP)- based fabric network, or as an alternative to SCSI on Fibre Channel (SCSI_FCP aka FCP aka FC). The SCSI command set dates back to the 1980s, having been deployed on physical parallel cabling and later on other transports, including Fibre Channel, Serial Attached SCSI (SAS), and iSCSI.
The reason it's time for NVMe over Fabric (NVMeoF), and specifically NVMeoF using TCP and RDMA, to let iSCSI begin its slow retirement journey, is the evolution of the NVMe protocol command set and the expansion of its ecosystem as a modern, ground-up, streamlined server storage I/O protocol command set.
Keep in mind that there are two aspects in play with NVMeoF, which are similar to iSCSI and Fibre Channel-based FCP: the upper layer or protocol command set (e.g., NVMe and SCSI), and media through which these command sets are implemented via various interfaces such as TCP or RDMA on Ethernet, via InfiniBand, Fibre Channel, or physical PCIe, among others.
Ethernet has established itself as the dominant network interface, supporting various upper layers, such as TCP, and increasing its speed. Likewise, InfiniBand and Fibre Channel continue to increase their speeds and maintain their deployment roles in some environments.
Besides supporting faster networks, the NVMe command set was architected and has been deployed to support the current and evolving generations of processors with multiple cores, enabling more concurrent I/O operations and compute threads with less CPU overhead due to a modern, streamlined I/O stack and associated native drivers.
Why NVMeoF (over TCP or RDMA)
Leverage the combined improved benefits of NVMe as a server storage I/O communications protocol, along with TCP networking and industry-standard Ethernet as a communications fabric. With the NVMe command protocol server storage, I/O processing is streamlined and optimized for modern high-speed, low-latency network fabrics, such as Ethernet, as the transport.
The NVMe command set, compared to the SCSI command set, enables faster I/O processing with lower latency, higher IOPs, greater bandwidth, and more transactions, while increasing concurrency and the number of threads and reducing CPU usage per I/O operation. Similar to the SCSI command set, which has been deployed on various industry-standard transport interfaces, the NVMe command set is also deployed across various transports. For example, SCSI has been supported on IP (iSCSI), Fibre Channel (SCSI_FCP, e.g., FCP), Serial Attached SCSI (SAS), and Parallel SCSI, among others.
Likewise, the NVMe command set has been implemented via PCIe, including U.2, as well as over fabrics (e.g., NVMe over Fabric, aka NVMeoF), most notably with TCP and RDMA, along with some NVMe over Fibre Channel. In addition to being a modern, streamlined command set, NVMe also supports more devices, queues, and sessions, and is optimized with host-server initiator and target-side stacks. An example of how NVMe is being embraced from a software support standpoint is Microsoft's production release of a new, re-architected, optimized I/O stack as part of Windows Server 2025 in December 2025. Recently, Microsoft released, as part of the latest vnext insiders preview build, an all-new NVMeoF (TCP & RDMA) initiator for testing and evaluation.
NVMe has proven itself as a command set using various transports for use as a target for various SSD and flash storage devices (e.g., back-end) in servers, clients, and storage systems, as well as a front-end alternative to SCSI_FCP (e.g., FCP or FC) and iSCSI among others on storage systems, and software-defined storage solutions. Also, keep in mind that while the SCSI command set dates back to at least the early 1990s for general-purpose access of Magnetic Tape, CD/DVD, HDD, and later SSD, NVMe developed in the last decade was created from the ground up for solid-state devices (SSDs), including flash, among other persistent storage mediums.
Why NVMeoF (TCP) vs iSCSI
It would be, and is, too easy to say the 2000s called and want iSCSI back; however, tongue-in-cheek, there is some reality to that. However, looking closer, iSCSI evolved in the early 2000s as a low-cost SCSI command set alternative to Fibre Channel (SCSI_FCP, e.g., FCP or FC), as well as the survivor of the block IP storage wars (e.g., iFCP, FCIP, iSCSI, etc.) for general-purpose IP-based SCSI storage access.
Fibre Channel-based SCSI (FCP) went on to dominate higher-performance fabric- or networked-storage, aka storage area networks (SANs), with iSCSI having some success in other areas alongside file-based IP storage access via NFS & SMB, among others.
Now that we are in the mid-2020s, the ecosystem around NVMe has matured and continues to do so, with full-stack NVMe solutions, hardware- and software-based initiators, native NVMe drivers, target-based storage systems, and storage devices using various transports. NVMe has evolved from direct-attached PCIe card slots to PCIe U.2 & U.3, M.2 and EDSFF slots, as well as NVMe over Fabrics including TCP and RDMA, among others.
The benefit of using NVMeoF vs iSCSI is lower latency, due to native NVMe commands over TCP being streamlined, vs older SCSI encapsulation and associated cumbersome driver stacks. Besides the streamlined drivers and transports, NVMeoF also provides massive parallelism and multi-threading to boost server storage I/O while leveraging today's multi-core processors and offload capabilities.
The net result is more I/O operations supporting higher IOPs, bandwidth, and transactions per second, with lower latency and lower CPU usage, resulting in greater productivity and better economics for databases, virtualization, AI/ML, and other block-based workloads.
Who supports NVMe and NVMeoF?
Most host and client operating systems support NVMe or NVMeoF initiators (e.g., Linux, VMware, Microsoft Windows [in the current Insider build], among others). There are also hardware adapter-based NVMe initiators, such as those from Broadcom, Chelsio, and NVIDIA. There are software NVMe and NVMe target packages for many platforms, such as Linux-based NVMe, nvme-tcp, nvme-rdma, nvme-fc, nvmet, nvmet-tcp, and SPDK (Storage Performance Development Kit), among others.
Besides server- or client-side support, there are storage and server hardware chassis building blocks that support NVMe, as well as storage system solutions from Dell, HPE, Hitachi, NetApp, Pure, among others. Within large cloud service providers such as AWS, Microsoft Azure, and Google Cloud Platform (GCP), NVMe is also widely used across their platform ecosystems.
Why it's time for NVMeoF to let iSCSI begin its slow retirement journey This is not to say that iSCSI is dead or that it has no future; rather, NVMeoF and its ecosystem have evolved and are ready to do more. Likewise, the SCSI command set is not dead; it's still used with SAS, Fibre Channel (FCP), iSCSI, etc. However, NVMe has evolved and is seeing broad adoption from server and client attachment to storage devices and storage systems over various transport interfaces and media (PCIe, U.2/U.3, M.2, EDSFF, Ethernet, and fabrics).
Storage systems have also evolved, adding front-end support for NVMeoF and back-end attachment of NVMe flash and SSDs. With the combination of server, client and other software platforms having or in public release review, new streamlined native NVMe drivers and I/O stacks along with NVMeoF initiators (or targets), now is the time to look at NVMeoF as a replacement or alternative to iSCSI, and perhaps even Fibre Channel in the future to support existing and legacy workloads as well as new and emerging application landscapes and their demanding server storage I/O and compute needs (e.g. AI among others).
Additional Resources Where to learn more
Microsoft Windows Server Insider Build NVMeoF Initiator (Blog post) NVMe Linux Driver and related info Announcing Native NVMe in Windows Server 2025 (Microsoft Post) Introducing the Windows NVMe-oF Initiator Preview in Windows Server Insiders Builds (Microsoft Post) Windows Server Insider Builds (Microsoft Downloads) ToE NVMeoF TCP Performance Line Boost Performance Reduce Costs (blog post) TheNVMeplace.com (Various NVMe resources) Azure Cloud Storage here (Microsoft Post) Microsoft Azure Data Box (Blog Post) Azure Elastic SAN from Cloud to On-Prem here (Blog Post) Cloud and Software Defined Data Infrastructure topics hereAdditional learning experiences along with common questions (and answers) pertaining to SCSI, Fibre Channel, NVMe, Cloud, Hardware, Software, Services, techniques, server, storage, I/O networking, data protection among other topics are found in my Software Defined Data Infrastructure Essentials book.
What this all means
Now is a good time to look into NVMe and, specifically, NVMe over Fabric (NVMeoF) if you have not recently done so, to refresh or learn what it can do. Likewise, if you are using iSCSI or Fibre Channel-based SCSI_FCP (e.g., not FICON), now is a good time to review or refresh your understanding of NVMeoF and where it fits into future plans for block storage. For those who say block storage is dead and everything is object storage, file storage, or even table storage, that's fine, as those are all companions to block storage in a balanced ecosystem, each with its own uses, roles, and fits.
Ok, nuff said. Cheers GsGreg Schulz - Ten time Microsoft MVP Cloud and Data Center Management and Azure Storage, along with previous ten-time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.
Microsoft Windows Server Insider Build NVMeoF Initiator
Microsoft Windows Server Insider Build NVMeoF Initiator
In case you haven't heard, in addition to recently announcing a new NVMe native driver for Windows Server 2025 back in December 2025, Microsoft has now introduced a new Windows NVMe over Fabrics (NVMeoF, aka NVMe-oF) Initiator Preview in the latest Windows Server Insiders Builds.
With the preview of this new NVMeoF initiator, Microsoft is moving closer to delivering enhanced server storage I/O performance by embracing NVMe as both a native storage target and a native NVMe host server initiator. While the new NVMe native storage stack driver was released for production back in December 2025, this new host initiator capability is available as a preview in the latest Windows Server insider build.
By adding a native NVMeoF initiator, Microsoft is enabling organizations to use shared networked block software-defined and SAN storage using the faster NVMe protocol, rather than traditional SCSI/iSCSI/SCSI_FCP(FC) protocol-based interfaces. In addition to supporting native direct-attached NVMe storage, Microsoft Windows servers (insider build) now support the streamlined NVMe server storage I/O stack over networks, including Ethernet and RDMA fabrics.
Additional Resources Where to learn more
Announcing Native NVMe in Windows Server 2025 (Microsoft Post) Introducing the Windows NVMe-oF Initiator Preview in Windows Server Insiders Builds (Microsoft Post) Windows Server Insider Builds (Microsoft Downloads) TheNVMeplace.com (Various NVMe resources) Azure Cloud Storage here (Microsoft Post) Microsoft Azure Data Box (Blog Post) Azure Elastic SAN from Cloud to On-Prem here (Blog Post) Cloud and Software Defined Data Infrastructure topics hereAdditional learning experiences along with common questions (and answers) pertaining to Cloud, Hardware, Software, Services, techniques, server, storage, I/O networking, data protection among other topics are found in my Software Defined Data Infrastructure Essentials book.
What this all means
While this new Windows Server host NVMe over Fabric (NVMeoF aka NVMe-oF) initiator for block storage is currently available as part of a Windows Server insiders build, it provides a means for organizations to begin testing native NVMe connectivity via Windows Servers to their existing SAN and other networked software defined storage servers via fabrics including Ethernet along with RDMA based. Learn more about this new initiator, along with how to try it out for yourself via this Microsoft blog post that includes instructions on how to setup your own NVMeoF storage target if you dont have one.
Ok, nuff said. Cheers GsGreg Schulz - Ten time Microsoft MVP Cloud and Data Center Management and Azure Storage, along with previous ten-time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.
Azure Cloud Storage Options
Azure Cloud Storage Options
Recently I was a guest on fellow Microsoft MVP Navika Chhauda podcast Tech Chat with Navika on YouTube. We discussed various Microsoft Cloud Storage Options, services, features and use cases. Here's the link to the podcast episode Understanding Azure Storage.
Our conversation included an overview of the various Azure Cloud Storage options and services along with some use cases. Our conversation covered Azure Cloud Storage options such as Blobs (e.g. objects) including Append, Block and Page blobs. We also discussed various File, Block including Azure Disk (for Azure VMs with NVMe SSD and HDDs). Another Azure Cloud Storage option is Azure Elastic SAN with various storage tiers.
We also discussed scenarios for Azure Data Lake Storage Gen2, Blob and file options, how they differ, as well as when to use the different types of storage. In addition, we discussed the integration of Azure Disk Storage with Azure Site recovery along with Azure Backup, as well as Data Box among other items.
Additional Resources Where to learn more
Learn more about: Azure Cloud Storage here Microsoft Azure Data Box here Azure Elastic SAN from Cloud to On-Prem here Navika Chauda on LinkedIn here Cloud and Software Defined Data Infrastructure topics hereAdditional learning experiences along with common questions (and answers) pertaining to Cloud, Hardware, Software, Services, techniques, server, storage, I/O networking, data protection among other topics are found in my Software Defined Data Infrastructure Essentials book.
What this all means
There is more to cloud storage than just objects and buckets or in Microsoft Azure parlance blobs and containers. Various storage options, tiers, categories and services are provided by the different cloud providers including Microsoft Azure. Some cloud storage options are for use within the cloud, while others can be used hybrid including from on-prem. These various Azure Cloud Storage Options support different workloads from new cloud native and Kubernetes based to traditional VM as well as on-prem, from data protection to on-line high performance, to AI among many others.
Ok, nuff said. Cheers GsGreg Schulz - Ten time Microsoft MVP Cloud and Data Center Management and Azure Storage, along with previous ten-time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.
Azure Cloud Storage Options
Azure Cloud Storage Options
Recently I was a guest on fellow Microsoft MVP Navika Chhauda podcast Tech Chat with Navika on YouTube. We discussed various Microsoft Cloud Storage Options, services, features and use cases. Here's the link to the podcast episode Understanding Azure Storage.
Our conversation included an overview of the various Azure Cloud Storage options and services along with some use cases. Our conversation covered Azure Cloud Storage options such as Blobs (e.g. objects) including Append, Block and Page blobs. We also discussed various File, Block including Azure Disk (for Azure VMs with NVMe SSD and HDDs). Another Azure Cloud Storage option is Azure Elastic SAN with various storage tiers.
We also discussed scenarios for Azure Data Lake Storage Gen2, Blob and file options, how they differ, as well as when to use the different types of storage. In addition, we discussed the integration of Azure Disk Storage with Azure Site recovery along with Azure Backup, as well as Data Box among other items.
Additional Resources Where to learn more
Learn more about: Azure Cloud Storage here Microsoft Azure Data Box here Azure Elastic SAN from Cloud to On-Prem here Navika Chauda on LinkedIn here Cloud and Software Defined Data Infrastructure topics hereAdditional learning experiences along with common questions (and answers) pertaining to Cloud, Hardware, Software, Services, techniques, server, storage, I/O networking, data protection among other topics are found in my Software Defined Data Infrastructure Essentials book.
What this all means
There is more to cloud storage than just objects and buckets or in Microsoft Azure parlance blobs and containers. Various storage options, tiers, categories and services are provided by the different cloud providers including Microsoft Azure. Some cloud storage options are for use within the cloud, while others can be used hybrid including from on-prem. These various Azure Cloud Storage Options support different workloads from new cloud native and Kubernetes based to traditional VM as well as on-prem, from data protection to on-line high performance, to AI among many others.
Ok, nuff said. Cheers GsGreg Schulz - Ten time Microsoft MVP Cloud and Data Center Management and Azure Storage, along with previous ten-time VMware vExpert. Author of Software Defined Data Infrastructure Essentials (CRC Press), as well as Cloud and Virtual Data Storage Networking (CRC Press), The Green and Virtual Data Center (CRC Press), Resilient Storage Networks (Elsevier) and twitter @storageio. Courteous comments are welcome for consideration. First published on https://storageioblog.com any reproduction in whole, in part, with changes to content, without source attribution under title or without permission is forbidden.
All Comments, (C) and (TM) belong to their owners/posters, Other content (C) Copyright 2006-2026 Server StorageIO and UnlimitedIO. All Rights Reserved. StorageIO is a registered Trade Mark (TM) of UnlimitedIO LLC.
Greg Schulz's Page
Profile Information
- Company name
- StorageIO
- My company is best described as a:
- Data Center Consultancy
- Company website
- http://storageio.com
- Jobtitle/position
- Sr. Advisor
- My role is best described as:
- Independent IT Advisor and Consultant
- I am:
- Independent Data Center Consultant (not tied to a vendor), Considered a Subject Matter Expert (see areas of expertise)
- Relevant qualifications & certifications (Please list certification authority + dates)
- Greg Schulz is an independent IT industry advisor, author, blogger and consultant. Greg has over 30 years of experience in across a variety of server, storage, networking, hardware, software and services platforms, architectures and paradigms. Greg gained his diverse industry insight experience from being in the trenches in IT data centers. He has held numerous positions including programmer, server and storage systems administrator, performance and capacity analyst, disaster recovery consultant, as well as a server and storage planner at companies including an electrical power generating & transmission utility, financial services and transportation firms. Shifting gears, Greg worked for several storage and networking companies in a variety of customer facing roles ranging from systems engineering and sales to marketing and Sr. technologists. After spending time as a customer and vendor, Greg became a Sr. Analyst at an IT analyst firm covering virtualization, SAN, NAS and associated storage management tools, techniques, best practices and technologies. In 2006, Greg leveraged those experiences of having been on the customer, vendor and analyst sides of the “IT table” to form the independent IT advisory consultancy firm Server and StorageIO Group (StorageIO).
- My main areas of expertise are:
- Cloud Computing, DCiM, Disaster Management, Energy Management, Green Initiatives, Infrastructure Management, IT Management, Migration, Networks, Planning, Power Generation/Distribution, Racks/Enclosures, Servers, Storage, Test/Measurement, Tools, Virtualisation
- More about me (How long have you been in the industry, expertise, career history, ambitions, website/blog, etc)
- Mr. Schulz has been involved with various storage related organizations including the Computer Measurement Group, Storage Networking Industry Association, and RAID Advisory Board among others. Greg is extensively published on a global basis and regularly appears in print, on-line as well as in person presenting and key note speaking at conferences, seminars and private events around the world on data infrastructure and related management topics. In addition to his thousands of reports, blogs, twitter tweets, columns, articles, tips, pod casts, videos and webcasts, Greg is also author of the books “The Green and Virtual Data Center” (CRC) and "Resilient Storage Networks – Designing Flexible Scalable Data Infrastructures” (Elsevier) in addition to being a co-author and contributor for many other book projects including “The Resilient Enterprise” (Symantec/Veritas). Greg is regularly quoted and interviewed as one of the most sought after independent IT advisors providing perspectives, commentary and opinion on industry activity. Greg has a B.A. in computer science and M.Sc. in software engineering from the University of St. Thomas. Learn more at www.storageioblog.com or twitter @storageio
Greg Schulz's Blog
Hot Popular New Trending Data Infrastructure Vendors and Service Providers to Watch
Posted on July 23, 2018 at 23:52 0 Comments 0 Likes
Here is the 2018 Hot Popular New Trending Data Infrastructure Vendors To Watch which includes startups as well as established vendors doing new things. This piece follows last year’s hot favorite trending data infrastructure vendors to watch…
ContinueDell Technology World 2018 Part I Announcement Summary
Posted on May 10, 2018 at 17:32 0 Comments 0 Likes
Dell Technology World 2018 Part I Announcement Summary

This is part one of a five-part series about Dell Technology World 2018 announcement summary. Last week (April 30-May 3) I traveled to Las Vegas Nevada (LAS) to attend Dell Technology World 2018 (e.g., DTW 2018) as a guest of Dell (that is a disclosure btw). There were several announcements along with…
Do you know about the new CLOUD Act data regulation?
Posted on April 6, 2018 at 20:07 0 Comments 0 Likes
Have you heard about the new CLOUD Act data regulation?
Have you heard about the new CLOUD Act data regulation?
The new CLOUD Act data regulation became law as part of the recent $1.3 Trillion (USD) omnibus U.S. government budget spending bill passed by Congress on March 23, 2018 and signed by…
ContinueMicrosoft Windows Server 2019 Insiders Preview Initial Test Drive Install
Posted on April 2, 2018 at 23:54 0 Comments 0 Likes
Microsoft Windows Server 2019 Insiders Preview
Microsoft Windows Server 2019 Insiders Preview has been announced. Windows Server 2019 in the past might have been named 2016 R2 also known as a Long-Term Servicing Channel (LTSC) release. Microsoft recommends LTSC…
ContinueData Protection Recovery Life After World Backup Day, Pre GDPR and Beyond
Posted on April 2, 2018 at 23:38 0 Comments 0 Likes
Data Protection Recovery Life Post World Backup Day Pre GDPR
It's time for Data Protection Recovery Life Post World Backup Day Pre GDPR Start Date.
The annual March 31 world backup day focus has come and gone once again.
However, that does not mean data protection including…
ContinueWelcome to
The Data Center Professionals Network
© 2026 Created by DCPNet Admin.
Powered by
![]()
Comment Wall (2 Comments)
You need to be a member of The Data Center Professionals Network to add comments!
Join The Data Center Professionals Network
Hi Greg I am rizwan.Shall we become friends?